You can combine tidySEM’s layout capabilities with lavaan or blavaan models for visualizations in ggsem. Both frequentist (lavaan) and Bayesian (blavaan) models work seamlessly with this workflow. blavaan objects work identically to how lavaan objects work with tidySEM package in ggsem.
Approach 1: Multi-Group Model with a Shared tidySEM Layout
This method uses tidySEM’s layout specification with multi-group models for consistent visualization across groups.
Use case: Single multi-group model object where ggsem automatically extracts group-specific parameters.
library(lavaan)library(ggsem)library(tidySEM)library(blavaan)lavaan_string <-'visual =~ x1 + x2 + x3 textual =~ x4 + x5 + x6 speed =~ x7 + x8 + x9'fit <-sem(lavaan_string, data = HolzingerSwineford1939, group ='school')bfit <-bsem(lavaan_string, data = HolzingerSwineford1939, group ='school')
While tidySEM can plot multiple SEMs at once using a multi-group model object, here we plot them with more aesthetic refinement using ggsem_builder() workflow with the pipe |> operator.
Implementation: You can create structured graph objects from multi-group models using tidySEM’s one layout system.
# Multi-group visualization with positioning (works for both lavaan and blavaan)ggsem_builder(type ='sem') |>add_group('P', model = fit, object = tidysem_object, y =25, level ='Pasteur') |>add_group('GW', model = fit, object = tidysem_object, y =-25, level ='Grant-White') |>launch()# Bayesian version works identicallyggsem_builder(type ='sem') |>add_group('P', model = bfit, object = tidysem_object_bayes, y =25, level ='Pasteur') |>add_group('GW', model = bfit, object = tidysem_object_bayes, y =-25, level ='Grant-White') |>launch()
Use case: Unified multi-group analysis with consistent visual structure across groups.
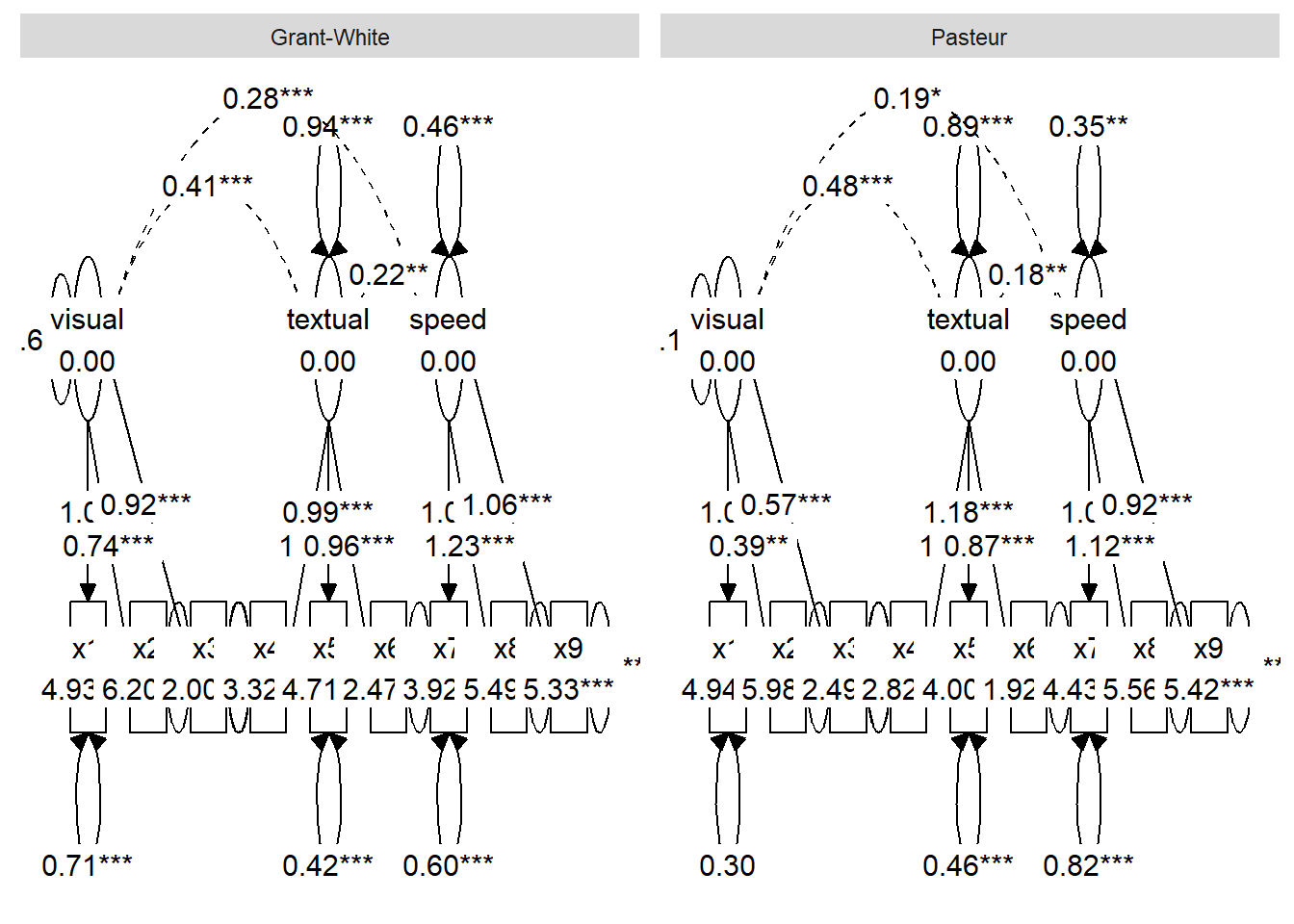
This figure shows a composite multi-group SEM figure (two groups) with significantly different paths highlighted (red color) in ggsem.
Figure 1. A composite multi-group SEM diagram with pre-loaded tidySEM visualization objects and lavaan model objects.
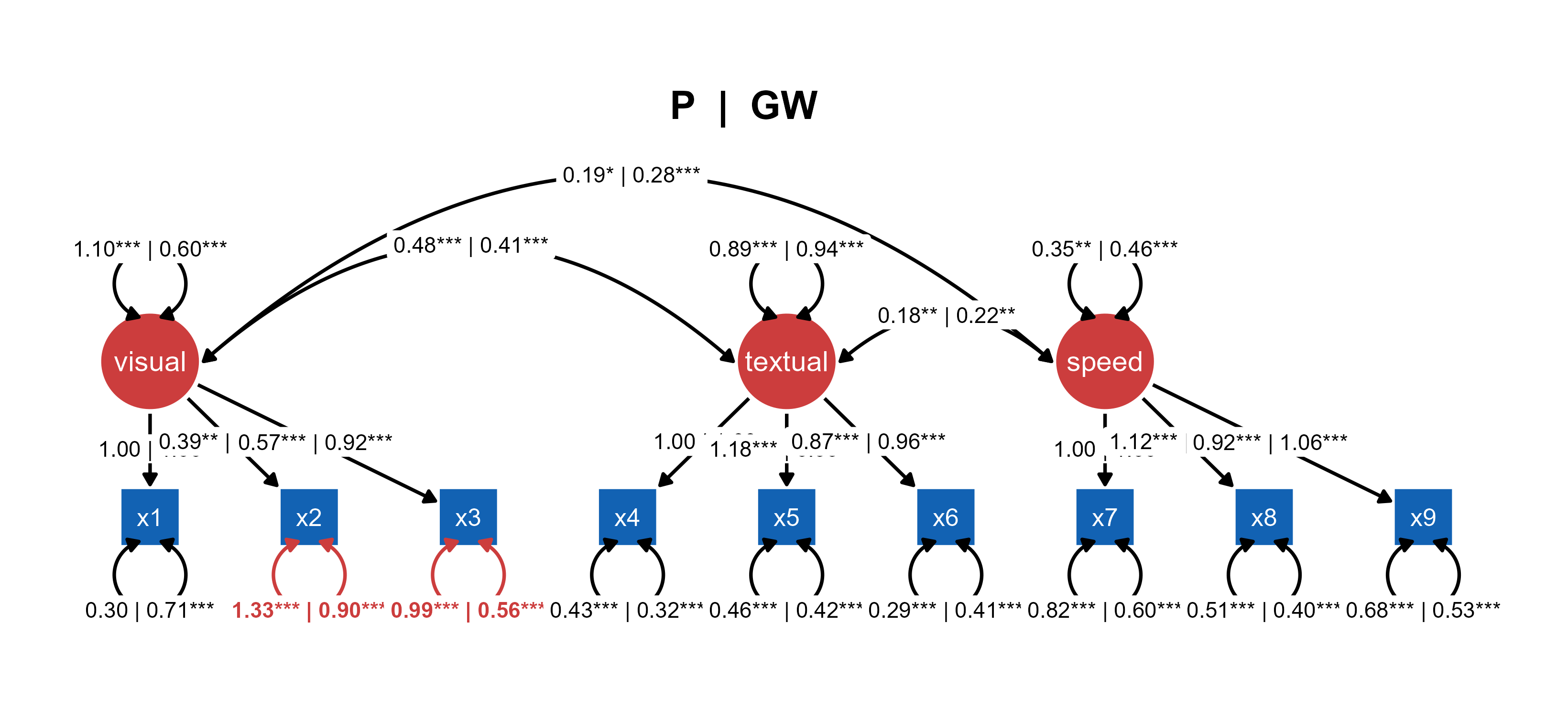
You can also generate a combined SEM of two groups with significantly different paths highlighted (Highlight Group Differences).
Figure 2. A combined multi-group SEM diagram with pre-loaded tidySEM visualization objects and lavaan model objects.
Approach 2: Separate Models with Shared Layout
Fit independent models to subgroup data while maintaining visual consistency through shared layout.
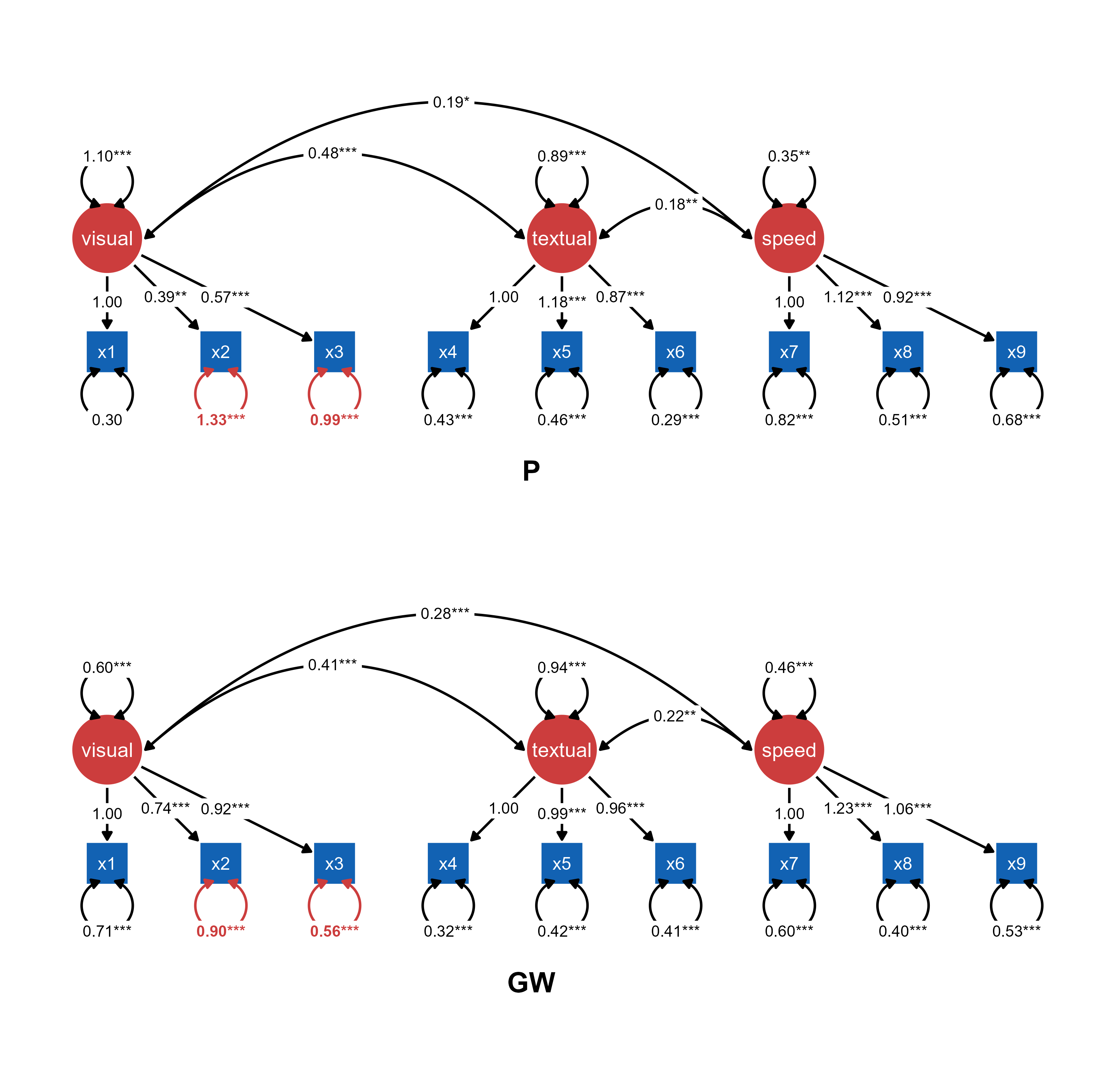
Use case: Pre-rendered diagrams for each group with explicit group-level specification using one model.
Visualization: Compare independently fitted models using identical layout structure.
ggsem_builder() |>add_group("Ptr", model = fitP, object = tidysem_objectP, y =-20) |>add_group("GW", model = fitGW, object = tidysem_objectGW, y =20) |>launch()
Use case: Independent group analyses with standardized visual presentation for direct comparison.
Approach 3: Multi-Group Model with Different tidySEM Layouts
Use a single multi-group model with customized tidySEM layouts for each group to highlight different visual perspectives while maintaining statistical consistency.
Use case: Completely independent models fitted to subgroup data.
Implementation: Apply distinct visual organizations to the same multi-group model for comparative analysis.
ggsem_builder(type ='sem') |>add_group('Pasteur', model = fit_multi, object = graph_pasteur, y =20, level ='Pasteur') |>add_group('Grant-White', model = fit_multi, object = graph_grantwhite, y =-20, level ='Grant-White') |>launch()
Use case: Comparative visualization of multi-group results using customized layouts that emphasize different aspects of the model structure for each group, while maintaining statistical consistency through shared parameter estimation.
Key Note: All three approaches work identically with both lavaan and blavaan models. Simply replace sem() with bsem() and the visualization workflow remains unchanged.