Chapter 7 Creating a Composite Figure by Subplotting
Citing the Guide and the Package
If you have used smplot2 for your composite visualizations, please cite the paper below:
Getting Started
In this section, we will plot a composite figure. This refers to a type of plot that has many panels with common information, such as the same x- and y-axes. Subplotting is referred to when we allocate subsets of data to particular panels but not others in the composite figure. We will make each panel (i.e., subplot) one-by-one, combine them into a composite figure, add a common legend, and then annotate it with texts and shapes using the functions from smplot2 package.
First, you need to load data (.csv file). When you are loading your own .csv file for your data analysis, make sure you place the .csv file of your interest in the folder that has been set to the working directory.
In this example, we will be using data from this paper:
Min, S. H., Baldwin, A. S., & Hess, R. F. (2019). Ocular dominance plasticity: a binocular combination task finds no cumulative effect with repeated patching. Vision Research, 161, 36-42.
We will be creating similar figures to those in the paper (ex. Figure 3A and Figure A2) using smplot2, as shown in the PDF.
## # A tibble: 6 × 4
## Subject Day Time Cbratio
## <chr> <fct> <dbl> <dbl>
## 1 S1 1 0 -0.421
## 2 S2 1 0 2.82
## 3 S3 1 0 1.69
## 4 S4 1 0 2.55
## 5 S5 1 0 -0.217
## 6 S6 1 0 0.626There are four columns in this data frame:
First,
Subjectrefers to each participant. There are 10 participants total.Next,
Dayrefers to the day of testing. The participants were tested on Day 1, 2, 3, 4 and 5. We will only use Day from 1 and 5.Timerefers to the number of minutes after an experimental manipulation (ex. monocular deprivation). These are 0, 3, 6, 12, 24 and 48 minutes, but in the data frame, it says 0, 1, 2, 3, 4 and 5; we will change the labels manually.The
Cbratiocolumn refers to the actual data that will be plotted here.
In the example below, the plots will have different colors based on Day (1 or 5). Therefore, the values in Day column have to be discrete, not continuous. To make them discrete, one needs to convert the Day column from double (continuous variable) to factor (discrete variable).
7.1 filter(), select() and summarise()
7.1.1 filter() for rows
To plot data of each subject separately, we need the data frame to show data only from one subject. This can be achieved as using filter():
## # A tibble: 12 × 4
## Subject Day Time Cbratio
## <chr> <fct> <dbl> <dbl>
## 1 S1 1 0 -0.421
## 2 S1 1 1 0.802
## 3 S1 1 2 1.01
## 4 S1 1 3 0.634
## 5 S1 1 4 -0.245
## 6 S1 1 5 -0.834
## 7 S1 5 0 2.42
## 8 S1 5 1 1.76
## 9 S1 5 2 1.91
## 10 S1 5 3 0.609
## 11 S1 5 4 0.811
## 12 S1 5 5 0.363- The first argument of
filter(),select(),summarise()andmutate()is a data frame. - The subsequent argument specifies how the data frame should be treated.
- The new printed result is a new data frame.
filter() is used to filter for rows that meet the requirement of your interest.
Here is another example.
## # A tibble: 60 × 4
## Subject Day Time Cbratio
## <chr> <fct> <dbl> <dbl>
## 1 S1 1 0 -0.421
## 2 S2 1 0 2.82
## 3 S3 1 0 1.69
## 4 S4 1 0 2.55
## 5 S5 1 0 -0.217
## 6 S6 1 0 0.626
## 7 S7 1 0 2.62
## 8 S8 1 0 1.42
## 9 S9 1 0 1.54
## 10 S10 1 0 3.05
## # ℹ 50 more rowsThe above code can be read as: filter for all rows of the data frame df that have 1 in the Day column.
Notice that S1 is a character because it has an alphabet. Therefore, it needs to be written as 'S1'. However, 1 of Day is double, which is essentially just a number digit. Therefore, it can be written as 1 with no quotation mark.
Let’s try another example.
day1 <- filter(df, Day == 1) # save the new data frame into a new variable
filter(day1, Subject == "S1") # this new data frame contains Day 1 and Subject 1 data only.## # A tibble: 6 × 4
## Subject Day Time Cbratio
## <chr> <fct> <dbl> <dbl>
## 1 S1 1 0 -0.421
## 2 S1 1 1 0.802
## 3 S1 1 2 1.01
## 4 S1 1 3 0.634
## 5 S1 1 4 -0.245
## 6 S1 1 5 -0.834The above code can be read as: filter for all rows of the data frame df that have 1 in the Day column. Save this new data frame as day1. Then, filter for all rows of the data frame day1 that have S1 in the Subject column.
The above can also be written like the one below:
## # A tibble: 6 × 4
## Subject Day Time Cbratio
## <chr> <fct> <dbl> <dbl>
## 1 S1 1 0 -0.421
## 2 S1 1 1 0.802
## 3 S1 1 2 1.01
## 4 S1 1 3 0.634
## 5 S1 1 4 -0.245
## 6 S1 1 5 -0.834The above can be read as: filter for all rows of the data frame df that have 1 in the Day column AND have S1 in the Subject column.
## # A tibble: 66 × 4
## Subject Day Time Cbratio
## <chr> <fct> <dbl> <dbl>
## 1 S1 1 0 -0.421
## 2 S2 1 0 2.82
## 3 S3 1 0 1.69
## 4 S4 1 0 2.55
## 5 S5 1 0 -0.217
## 6 S6 1 0 0.626
## 7 S7 1 0 2.62
## 8 S8 1 0 1.42
## 9 S9 1 0 1.54
## 10 S10 1 0 3.05
## # ℹ 56 more rowsThe above can be read as: filter for all rows of the data frame df that have 1 in the Day column OR have S1 in the Subject column. | represents OR, & represents AND.
7.1.2 select() for columns
If you wish to see the Cbratio column only (i.e., data only) for rows of df that have Day == 1 and Time == 0, you can write it like this:
day1_time0 <- filter(df, Day == 1 & Time == 0) # save the new data frame in the day1_time0 variable
select(day1_time0, Cbratio)## # A tibble: 10 × 1
## Cbratio
## <dbl>
## 1 -0.421
## 2 2.82
## 3 1.69
## 4 2.55
## 5 -0.217
## 6 0.626
## 7 2.62
## 8 1.42
## 9 1.54
## 10 3.05There are 10 rows (i.e., 10 subjects) in this filtered data frame and 1 column, which is Cbratio. The above can be read as: filter for all rows of the data frame df that have 1 in the Day column AND have 0 in the Time column. Then, store the new data frame in day1_time0. Then, select for Cbratio column from day1_time0.
select() is used to filter for columns that meet the requirement of your interest.
7.1.3 summarise() for grouped summaries
df contains individual data for all subjects on Days 1 and 5 across all time points. However, it does not contain average data either for each Day or Time.
summarise() can collapse multiple rows of observations into values such as the mean.
## # A tibble: 1 × 1
## average
## <dbl>
## 1 1.35However, in this case, we get an example of Cbratio across Subject, Day and Time. This average value itself is not so meaningful. If we wish to obtain the average for each Day and Time, we can use the function group_by() to group data for each day and time.
As it was the case before, the first argument of
group_by()is a data frame.The second argument of
group_by()is the name of the column through which you would like to group the data.
## # A tibble: 120 × 4
## # Groups: Day, Time [12]
## Subject Day Time Cbratio
## <chr> <fct> <dbl> <dbl>
## 1 S1 1 0 -0.421
## 2 S2 1 0 2.82
## 3 S3 1 0 1.69
## 4 S4 1 0 2.55
## 5 S5 1 0 -0.217
## 6 S6 1 0 0.626
## 7 S7 1 0 2.62
## 8 S8 1 0 1.42
## 9 S9 1 0 1.54
## 10 S10 1 0 3.05
## # ℹ 110 more rowsThe output of group_by() is a new data frame (it might appear exactly the same as before, ex. df). However, it will respond differently to summarise() because the rows of the data frame are now grouped based on day and time, as we have specified.
## `summarise()` has grouped output by 'Day'. You can override using the `.groups` argument.## # A tibble: 12 × 3
## # Groups: Day [2]
## Day Time Average_Cbratio
## <fct> <dbl> <dbl>
## 1 1 0 1.57
## 2 1 1 2.21
## 3 1 2 2.32
## 4 1 3 0.979
## 5 1 4 1.25
## 6 1 5 1.14
## 7 5 0 1.85
## 8 5 1 1.49
## 9 5 2 1.02
## 10 5 3 1.15
## 11 5 4 0.759
## 12 5 5 0.452This new data frame yields average for each Day and Time. We have now created a new column Average_Cbratio which stores all the average data of Cbratio.
Therefore, group_by() and summarise() are very useful together. They provide grouped summaries, such as the average. However, summarise() alone may not be so useful. group_by() alone is also rarely used.
Besides the average, one might also be interested in obtaining either standard deviation or standard error.
However, our df does not contain any data about the standard deviation or standard error per Day or Time, etc. Standard deviation can be calculated via sd() and standard error can be computed with sm_stdErr().
Below, we obtain standard error with the help of the summarise() function for each Day and Time.
## # A tibble: 1 × 1
## standard_error
## <dbl>
## 1 0.115As we have seen before, we see that standard_error has been calculated across all subjects, day and time. This is not so useful. We should use summarise() with group_by() so that each standard error could be for each Day and Time.
## `summarise()` has grouped output by 'Day'. You can override using the `.groups` argument.## # A tibble: 12 × 3
## # Groups: Day [2]
## Day Time standard_error
## <fct> <dbl> <dbl>
## 1 1 0 0.393
## 2 1 1 0.363
## 3 1 2 0.400
## 4 1 3 0.352
## 5 1 4 0.266
## 6 1 5 0.438
## 7 5 0 0.563
## 8 5 1 0.422
## 9 5 2 0.462
## 10 5 3 0.224
## 11 5 4 0.292
## 12 5 5 0.193This standard error is for each Day and Time across all subjects.
Now let’s obtain the mean and standard error of Cbratio for each Day and Time across all subjects using the data frame that has been grouped by Day and Time via group_by().
## `summarise()` has grouped output by 'Day'. You can override using the `.groups` argument.## # A tibble: 12 × 4
## # Groups: Day [2]
## Day Time Average StdError
## <fct> <dbl> <dbl> <dbl>
## 1 1 0 1.57 0.393
## 2 1 1 2.21 0.363
## 3 1 2 2.32 0.400
## 4 1 3 0.979 0.352
## 5 1 4 1.25 0.266
## 6 1 5 1.14 0.438
## 7 5 0 1.85 0.563
## 8 5 1 1.49 0.422
## 9 5 2 1.02 0.462
## 10 5 3 1.15 0.224
## 11 5 4 0.759 0.292
## 12 5 5 0.452 0.193The original df, which contains data for each subject, has now been transformed to a new data frame that contains grouped summaries, such as group averages and standard errors.
If you are interested in learning more about this topic (data transformation), please check out Chapter 5 of R for Data Science by Hadley Wickham (https://r4ds.had.co.nz/transform.html).
7.2 Plotting the averaged data with error bars
Plotting the averaged data can be done with a data frame that contains individual observation (ex. each subject, condition, etc). This data frame can be modified to only contain summary values, such as mean and standard error, using group_by() and summarise() together as shown above.
We will plot a similar graph to Figure 3A in the Vision Research paper (Min et al., 2019) in this section.
- A data frame that has grouped summary information (
group_by()andsummarise()), such as average and standard error across subject, is needed to plot a graph that shows the average data with error bars. geom_errorbar()is required to plot the error bar of the sample.- Legend title has been removed with the
theme()function. - Greek letter Delta is printed with
\u0394. - X-tick labels are originally 0, 1, 2, 3, 4, 5 (as specified in the df data frame). However, they can be manually changed using
labels =argument in thescale_x_continuous()function. - Legend label can also be changed in
labels =from thescale_color_manual()function because eachDayhas been defined by eachcolor; this is the case becausecolor = Dayinaes(..., ..., color = Day).
ggplot(data = by_day_time1, aes(x = Time, y = Average, color = Day)) +
geom_point(size = 4.5) +
geom_errorbar(aes(ymin = Average - StdError, ymax = Average + StdError), size = .5, width = .05) +
geom_smooth(method = "lm", se = F, size = 0.9) +
# lm = linear regression method
scale_x_continuous(
breaks = unique(df$Time),
labels = c("0", "3", "6", "12", "24", "48")
) +
sm_hgrid(legends = TRUE) +
scale_color_manual(
values = sm_color("blue", "orange"),
labels = c("Day 1", "Day 5")
) +
ggtitle("Recovery of the patching effect") +
xlab("Time after monocular deprivation (min)") +
ylab("\u0394 Contrast balance ratio (dB)") +
theme(
legend.justification = c(1, 0),
legend.position = c(0.96, 0.67),
legend.title = element_blank()
)## `geom_smooth()` using formula = 'y ~ x'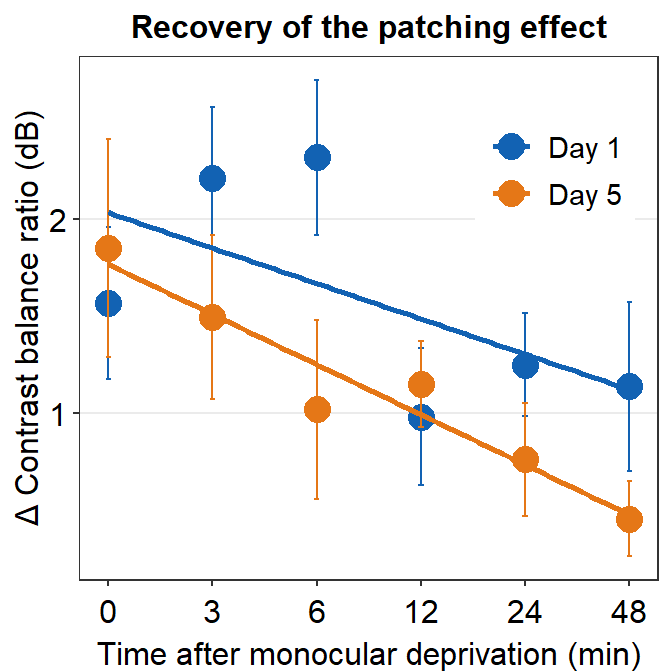
7.3 Plotting individual data
In this section, we will plot a similar graph to Figure A2 in the Vision Research paper (Min et al., 2019).
First, let’s plot data for each subject (S1-S9) except S10. Each panel shows the data of each subject for both Days 1 and 5.
df_s1 <- filter(df, Subject == "S1")
# rows of df that only contain S1 in the Subject column
# use df_s1 to plot the data of S1
plot_s1 <- ggplot(data = df_s1, aes(x = Time, y = Cbratio, color = Day)) +
geom_point(size = 4.5) +
geom_smooth(method = "lm", se = F, size = 0.9) +
# lm = linear regression method
scale_x_continuous(
breaks = unique(df$Time),
labels = c("0", "3", "6", "12", "24", "48")
) +
sm_hgrid() +
scale_color_manual(values = sm_color("blue", "orange")) +
scale_y_continuous(limits = c(-3, 5.5))
# axis text size is 1.5x the original font size.
print(plot_s1)## `geom_smooth()` using formula = 'y ~ x'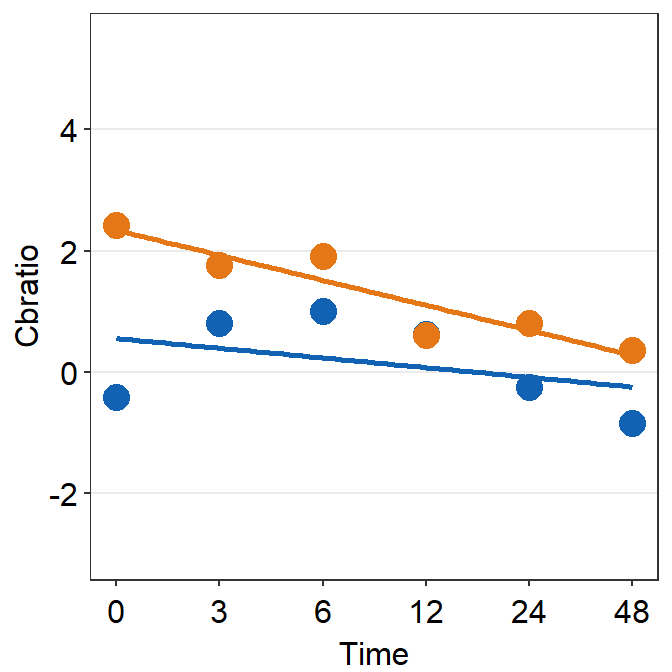
Then make each one for the other subjects (S2-S9).
df_s2 <- filter(df, Subject == "S2")
plot_s2 <- ggplot(data = df_s2, aes(x = Time, y = Cbratio, color = Day)) +
geom_point(size = 4.5) +
geom_smooth(method = "lm", se = F, size = 0.9) +
# lm = linear regression method
scale_x_continuous(
breaks = unique(df$Time),
labels = c("0", "3", "6", "12", "24", "48")
) +
sm_hgrid() +
scale_color_manual(values = sm_color("blue", "orange")) +
scale_y_continuous(limits = c(-3, 5.5))
# axis text size is 1.5x the original font size.
print(plot_s2)## `geom_smooth()` using formula = 'y ~ x'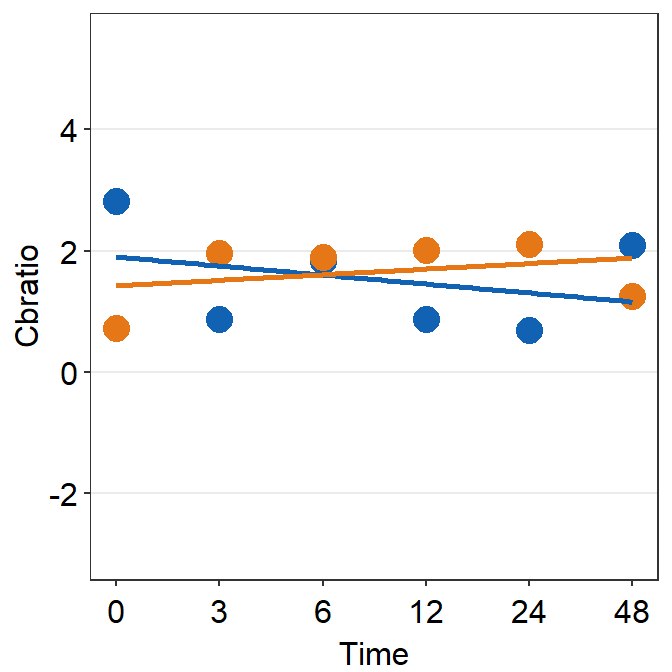
df_s3 <- filter(df, Subject == "S3")
plot_s3 <- ggplot(data = df_s3, aes(x = Time, y = Cbratio, color = Day)) +
geom_point(size = 4.5) +
geom_smooth(method = "lm", se = F, size = 0.9) +
# lm = linear regression method
scale_x_continuous(
breaks = unique(df$Time),
labels = c("0", "3", "6", "12", "24", "48")
) +
sm_hgrid() +
scale_color_manual(values = sm_color("blue", "orange")) +
scale_y_continuous(limits = c(-3, 5.5))
# axis text size is 1.5x the original font size.
print(plot_s3)## `geom_smooth()` using formula = 'y ~ x'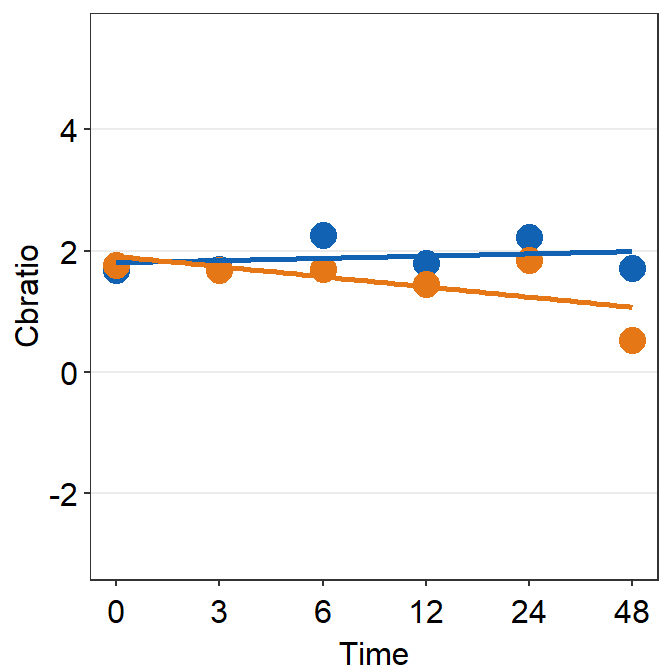
df_s4 <- filter(df, Subject == "S4")
plot_s4 <- ggplot(data = df_s4, aes(x = Time, y = Cbratio, color = Day)) +
geom_point(size = 4.5) +
geom_smooth(method = "lm", se = F, size = 0.9) +
# lm = linear regression method
scale_x_continuous(
breaks = unique(df$Time),
labels = c("0", "3", "6", "12", "24", "48")
) +
sm_hgrid() +
scale_color_manual(values = sm_color("blue", "orange")) +
scale_y_continuous(limits = c(-3, 5.5))
# axis text size is 1.5x the original font size.
print(plot_s4)## `geom_smooth()` using formula = 'y ~ x'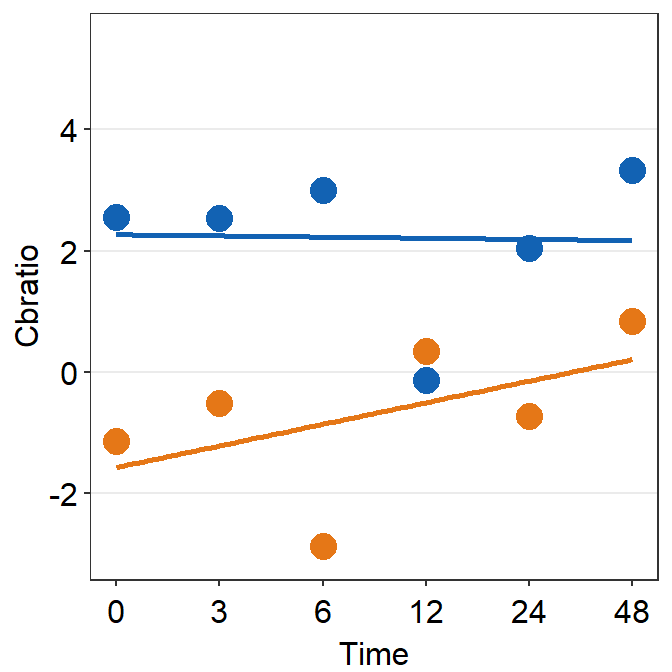
# Subject 5
df_s5 <- filter(df, Subject == "S5")
# rows of df that only contain S5 in the Subject column
plot_s5 <- ggplot(data = df_s5, aes(x = Time, y = Cbratio, color = Day)) +
geom_point(size = 4.5) +
geom_smooth(method = "lm", se = F, size = 0.9) +
# lm = linear regression method
scale_x_continuous(
breaks = unique(df$Time),
labels = c("0", "3", "6", "12", "24", "48")
) +
sm_hgrid(legends = FALSE) +
scale_color_manual(values = sm_color("blue", "orange")) +
scale_y_continuous(limits = c(-3, 5.5))
print(plot_s5)## `geom_smooth()` using formula = 'y ~ x'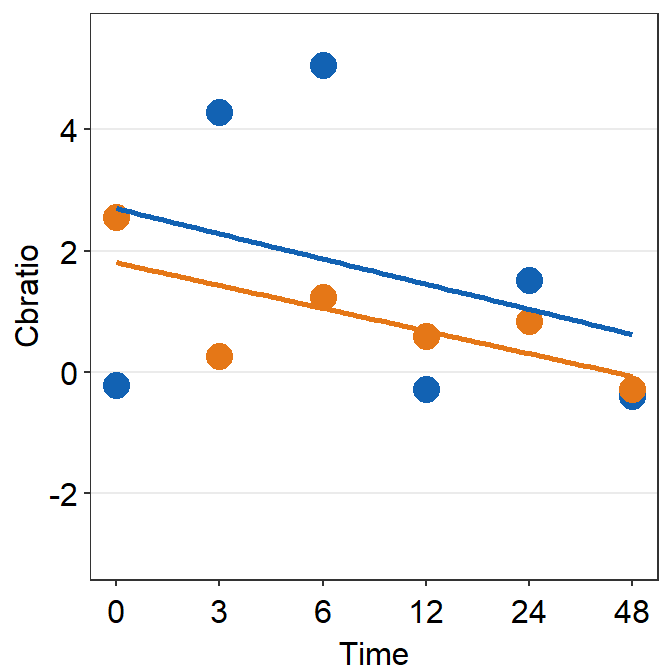
# Subject 6
df_s6 <- filter(df, Subject == "S6")
# rows of df that only contain S6 in the Subject column
plot_s6 <- ggplot(data = df_s5, aes(x = Time, y = Cbratio, color = Day)) +
geom_point(size = 4.5) +
geom_smooth(method = "lm", se = F, size = 0.9) +
# lm = linear regression method
scale_x_continuous(
breaks = unique(df$Time),
labels = c("0", "3", "6", "12", "24", "48")
) +
sm_hgrid() +
scale_color_manual(values = sm_color("blue", "orange")) +
scale_y_continuous(limits = c(-3, 5.5))
# axis text size is 1.5x the original font size.
print(plot_s6)## `geom_smooth()` using formula = 'y ~ x'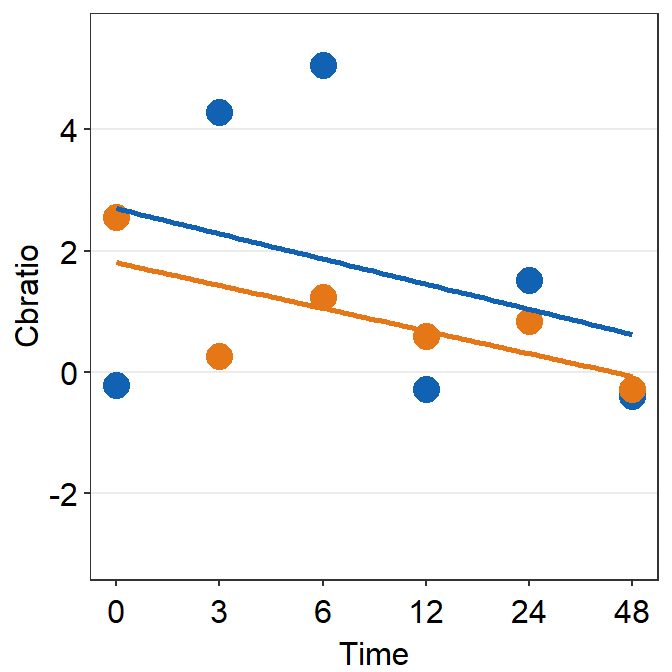
df_s7 <- filter(df, Subject == "S7")
plot_s7 <- ggplot(data = df_s7, aes(x = Time, y = Cbratio, color = Day)) +
geom_point(size = 4.5) +
geom_smooth(method = "lm", se = F, size = 0.9) +
# lm = linear regression method
scale_x_continuous(
breaks = unique(df$Time),
labels = c("0", "3", "6", "12", "24", "48")
) +
sm_hgrid() +
scale_color_manual(values = sm_color("blue", "orange")) +
scale_y_continuous(limits = c(-3, 5.5))
# axis text size is 1.5x the original font size.
print(plot_s7)## `geom_smooth()` using formula = 'y ~ x'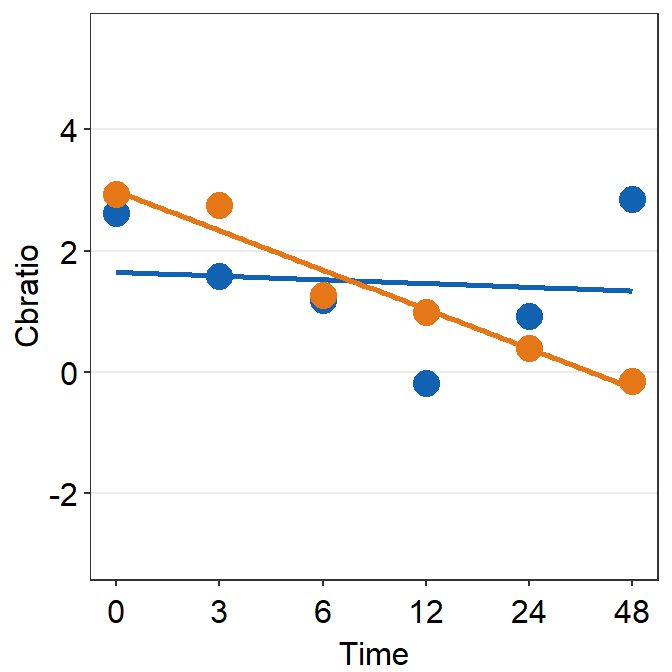
df_s8 <- filter(df, Subject == "S8")
plot_s8 <- ggplot(data = df_s8, aes(x = Time, y = Cbratio, color = Day)) +
geom_point(size = 4.5) +
geom_smooth(method = "lm", se = F, size = 0.9) +
# lm = linear regression method
scale_x_continuous(
breaks = unique(df$Time),
labels = c("0", "3", "6", "12", "24", "48")
) +
sm_hgrid() +
scale_color_manual(values = sm_color("blue", "orange")) +
scale_y_continuous(limits = c(-3, 5.5))
# axis text size is 1.5x the original font size.
print(plot_s8)## `geom_smooth()` using formula = 'y ~ x'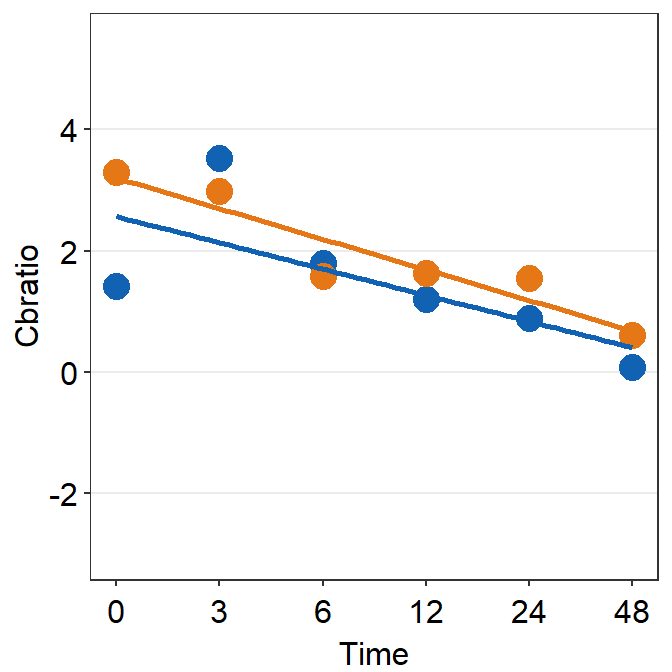
# Subject 9
df_s9 <- filter(df, Subject == "S9")
plot_s9 <- ggplot(data = df_s9, aes(x = Time, y = Cbratio, color = Day)) +
geom_point(size = 4.5) +
geom_smooth(method = "lm", se = F, size = 0.9) +
# lm = linear regression method
scale_x_continuous(
breaks = unique(df$Time),
labels = c("0", "3", "6", "12", "24", "48")
) +
sm_hgrid() +
scale_color_manual(values = sm_color("blue", "orange")) +
scale_y_continuous(limits = c(-3, 5.5))
# axis text size is 1.5x the original font size.
print(plot_s9)## `geom_smooth()` using formula = 'y ~ x'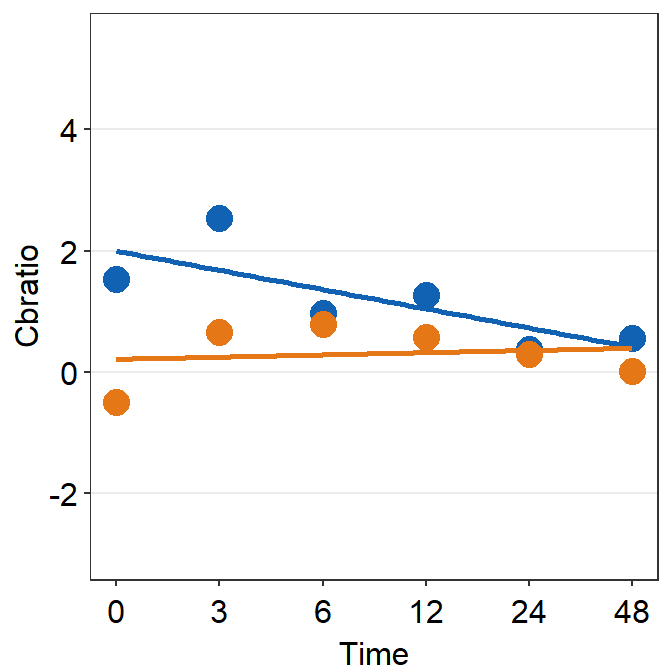
This is quite a repetitive process! Fortunately, you can also generate the nine plots using a programmatic approach, which involves loop around the nine subjects using one code chunk. This method is described in section 7.7.
7.4 Putting multiple plots together (a composite figure) - sm_put_together()
Each panel output has to be stored in a list using the function list(). X-axis label can be specified using sm_common_xlabel(), which has x and y arguments for setting the location of the label. Y-axis label is specified using sm_common_ylabel() with the same x and y arguments. The title can be set using sm_common_title().
all_plots <- list(
plot_s1, plot_s2, plot_s3,
plot_s4, plot_s5, plot_s6,
plot_s7, plot_s8, plot_s9
)
xlabel <- sm_common_xlabel("Minutes after monocular deprivation", x = 0.52, y = 0.6)
ylabel <- sm_common_ylabel("\u0394 Contrast balance ratio (dB)")
title <- sm_common_title("Individual data", y = 0.2)
plots_tgd <- sm_put_together(all_plots,
title = title, xlabel = xlabel,
ylabel = ylabel, ncol = 3, nrow = 3,
hmargin = -5, wmargin = -5
)Now let’s put them together in a 3x3 figure (3 rows, 3 columns) using the function sm_put_together(). So, ncol and nrow are set to 3 in sm_put_together(). The function automatically removes tick labels in both x- and y-axes in inner panels, and keeps them on the outer panels, so that combined plot looks clean. Also, the hmargin argument can be set to adjust the blank space of height between panels; the wmargin argument can be set to adjust the blank space of width between panels. Their values can be both negative (less blank space) and positive (more blank space). I suggest you use values from -5 to 5 for hmargin and wmargin.
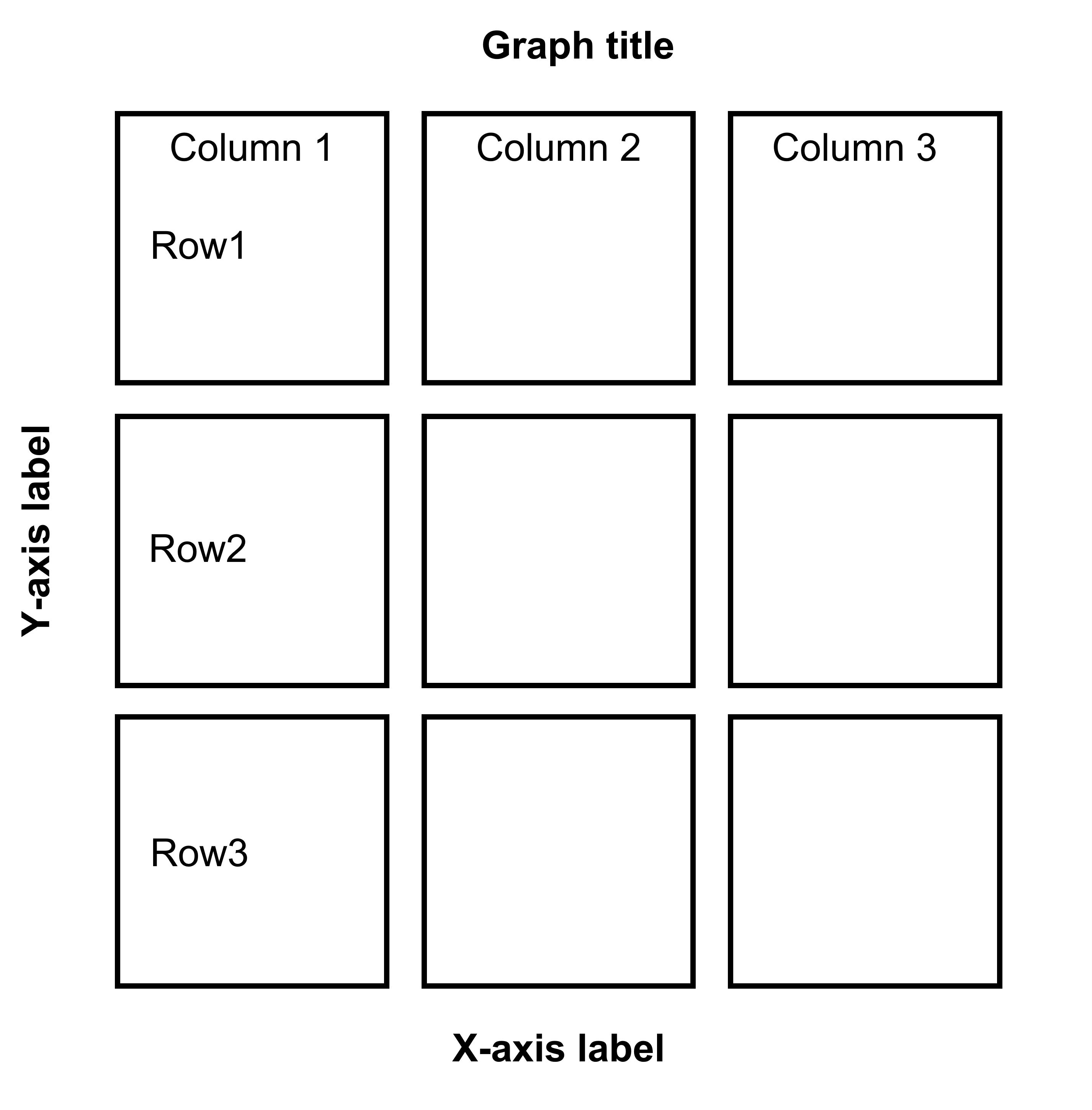
Figure 7.1: 3x3 figure. It has 3 columns and 3 rows

ggsave(), a function from the ggplot2 package, can be used to save the graph as an image/vector file with a specified dimension of the figure, using width and height arguments (inches).
Open together1.png in your directory folder. The figure is clean but it lacks a few things: 1) label for each panel, 2) legend. With examples below, we will add them.
all_plots2 <- sm_panel_label(all_plots,
x = 0.1, y = 0.9, panel_tag = "1", panel_pretag = "S", text_size = 5,
text_color = "black", fontface = "bold"
)Here, we include a label for each panel, which represents the data of each subject, using sm_panel_label().
The function sm_panel_label() has a few arguments. x and y determine the location of the panel label; 0.5 represents its origin in the middle of the panel. panel_tag determines the character string that will be used for enumeration. In this example, panel_tag = "1" is chosen so there will be a sequence of numbers. Other options include: 1) panel_tag = "A" for uppercase letters, 2) panel_tag = "a" for small case letters, 3) panel_tag = "I" for upper roman numerals, and 4) panel_tag = "i" for lower roman numerals. There are also tag labels that can set to be consistent across panels: these are panel_pretag and panel_posttag. panel_pretag comes before panel_tag (as shown in this example, in the form of S, ex. S1), and panel_posttag comes after panel_tag.
plots_tgd2 <- sm_put_together(all_plots2,
title = title, xlabel = xlabel,
ylabel = ylabel, ncol = 3, nrow = 3,
hmargin = -5, wmargin = -5
)
plots_tgd3 <- sm_add_legend(plots_tgd2,
x = .88, y = 0.05, sampleplot = all_plots2[[1]],
direction = "horizontal", border = FALSE
)As before, we then combine the list of plots with panel label (all_plots2) and the labels for the common x- and y-axes, as well as the title of the combined figure using sm_put_together(). The arguments of sm_put_together() have to be written in this order unless they are specified (ex. sm_put_together(all_plots=all_plots, xlabel=xlabel, title=title)). We reduce the margin of width and height blank space between panels by setting hmargin=-5 and vmargin=-5.
Next, we add legend using sm_add_legend(). It has a number of arguments. First, the combined figure (output from sm_put_together()) must be provided. Next, x and y are the location of the legend in the coordinates of the combined figure (0 to 1), where x=0.5 and y=0.5 represents the center of the combined figure. sampleplot has to be provided, which in this case one of the plots in the plots_tgd2 list, so that the function sm_add_legend() can derive a legend for the whole combined plot. The direction (or orientation) of the legend can also be set as horizontal or vertical; in this case, we set it to direction = horizontal.
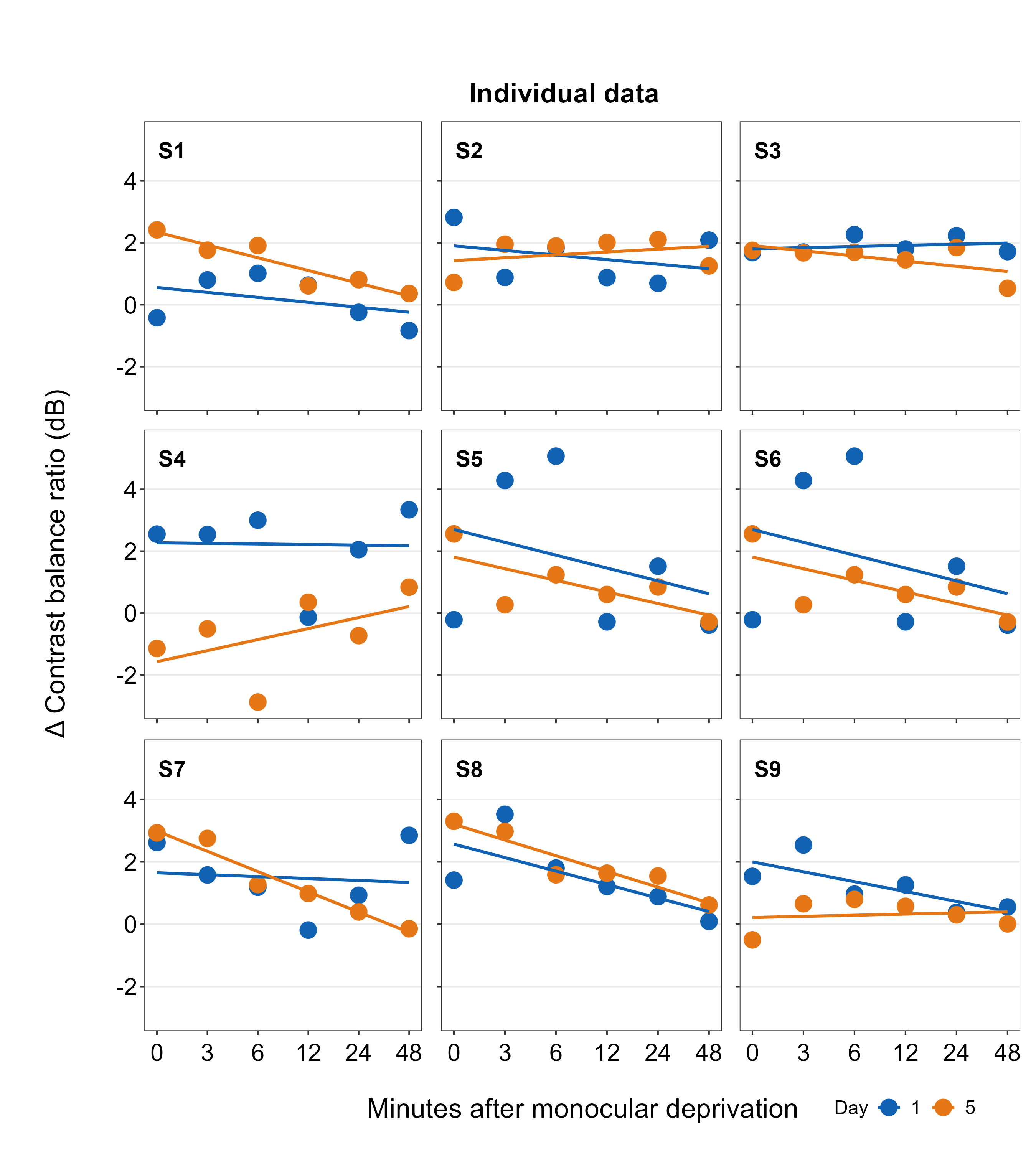
The border of the legend can also be included by setting border = TRUE. We can also increase the amount of spacing within the legend using legend_spacing argument from sm_add_legend. This change is subtle but you will definitely notice it.
plots_tgd3b <- sm_add_legend(plots_tgd2,
x = .88, y = 0.05, sampleplot = all_plots2[[1]],
direction = "horizontal", border = TRUE, legend_spacing = 1
)## `geom_smooth()` using formula = 'y ~ x'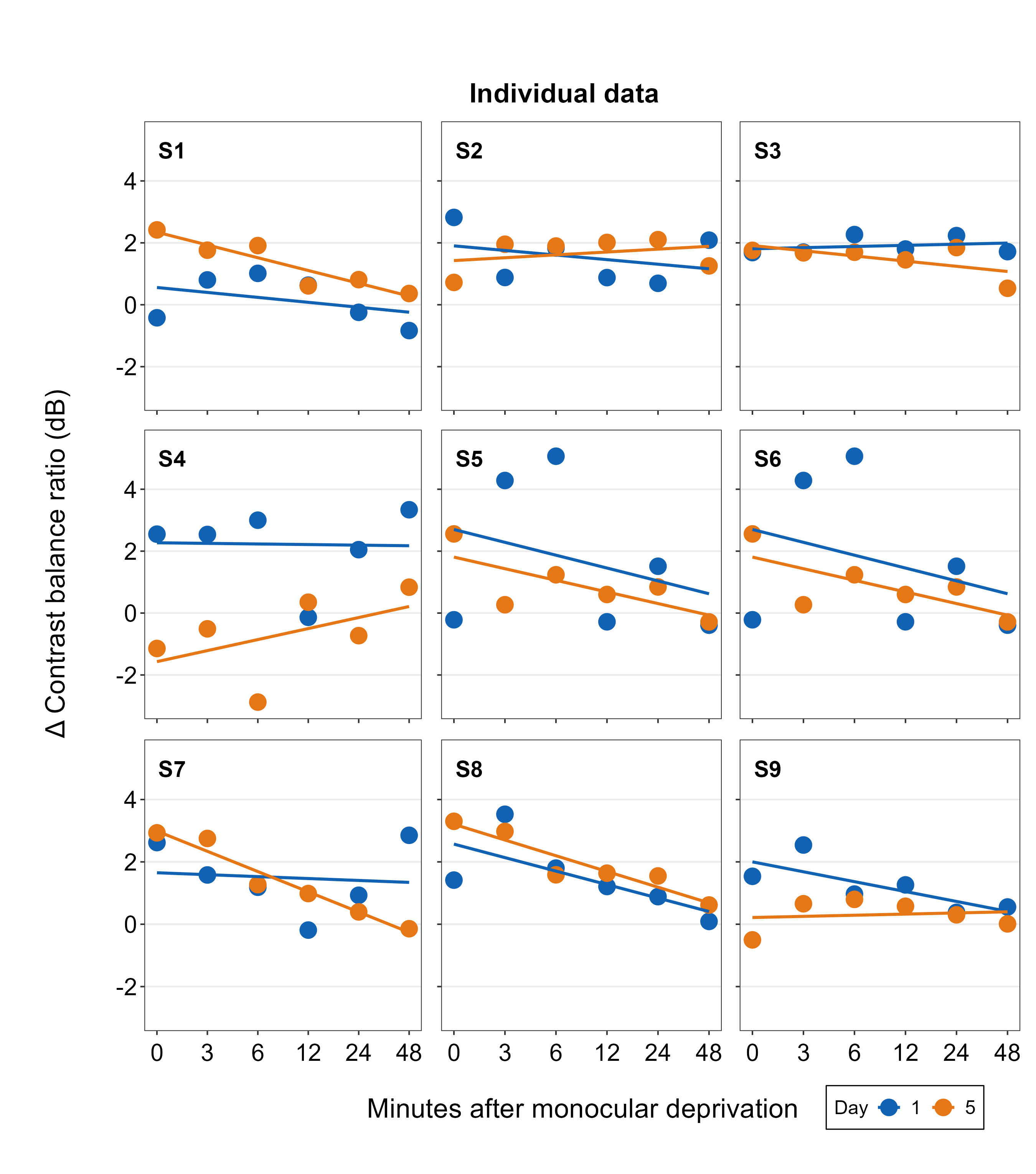
You can even make a separate legend on your own with full customization using sm_common_legend(), then add the legend to the combined plot using sm_add_legend(). We will do this by first making a combined figure with two rows and five columns (nrow=2 and ncol=5). The legend can be on the 10th panel because its empty.
legend <- ggplot(data = df_s9, aes(x = Time, y = Cbratio, color = Day)) +
geom_point(size = 2.5) +
scale_color_manual(
values = sm_color("blue", "orange"),
labels = c("Data from Day 1 ", "Data from Day 5 ")
) +
scale_shape_manual(
values = c(21, 22),
labels = c("Data from Day 1 ", "Data from Day 5 ")
) +
sm_common_legend(title = FALSE, legend_spacing = 1)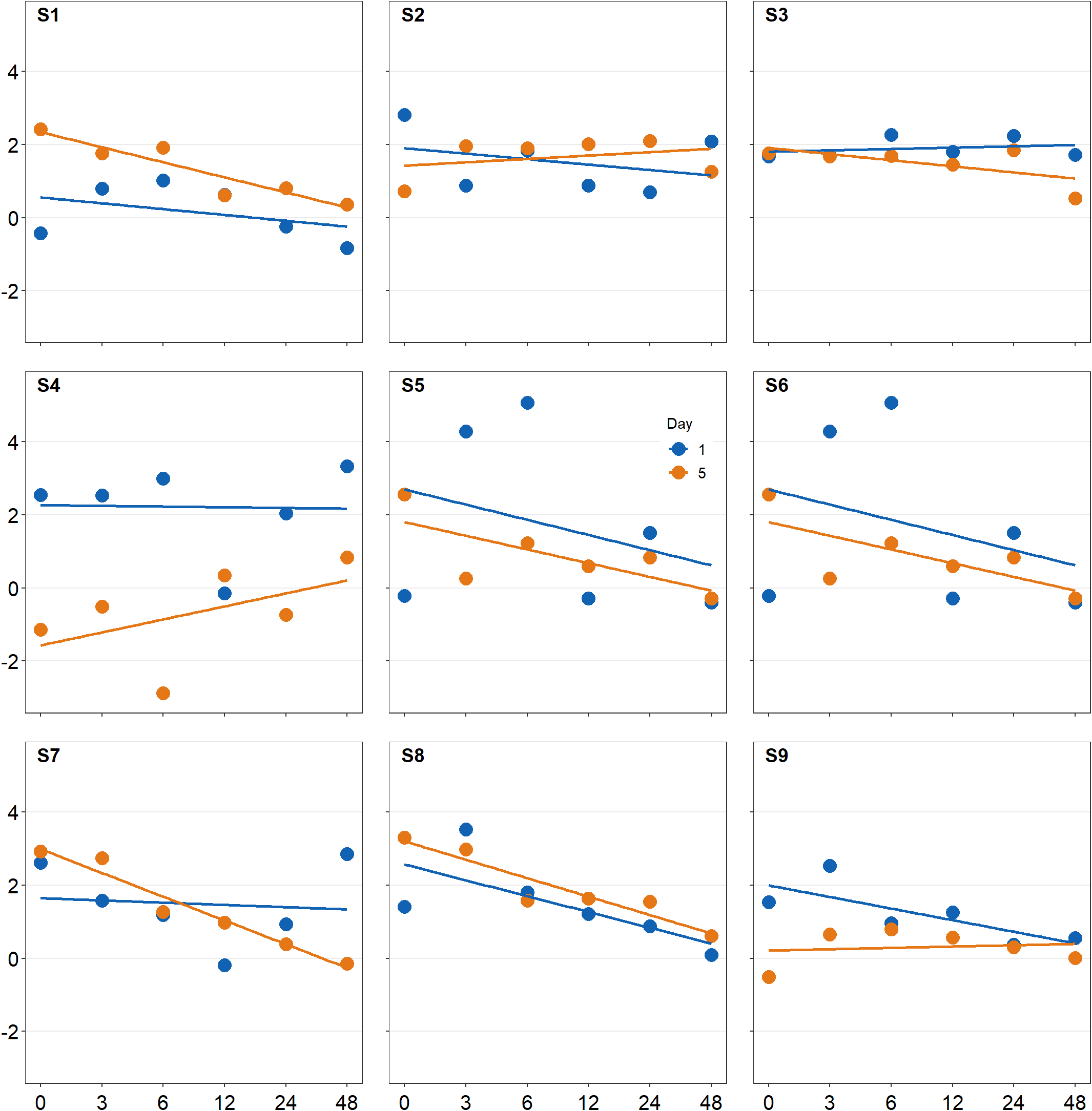
Basically, legend that is created with sm_common_legend() is a new plot with no points; however, you still need to draw the same points and include other features from other sub-panels to make sure that they are included in the legend. Notice that legend labels have been customized as well by adjusting the labels within scale_color_manual() and scale_shape_manual(). The title has been removed by setting title = FALSE.
The legend can then be added to the combined plot using sm_add_legend(). If you provide a separate legend, then other arguments of the function will be ignored, such as direction and border from sm_add_legend() because these arguments are used to derive a legend based on sampleplot. x and y describe the coordinates of the legend in the composite plot (output from sm_put_together(): plots_tgd2), and these are supplied in the sm_add_legend().
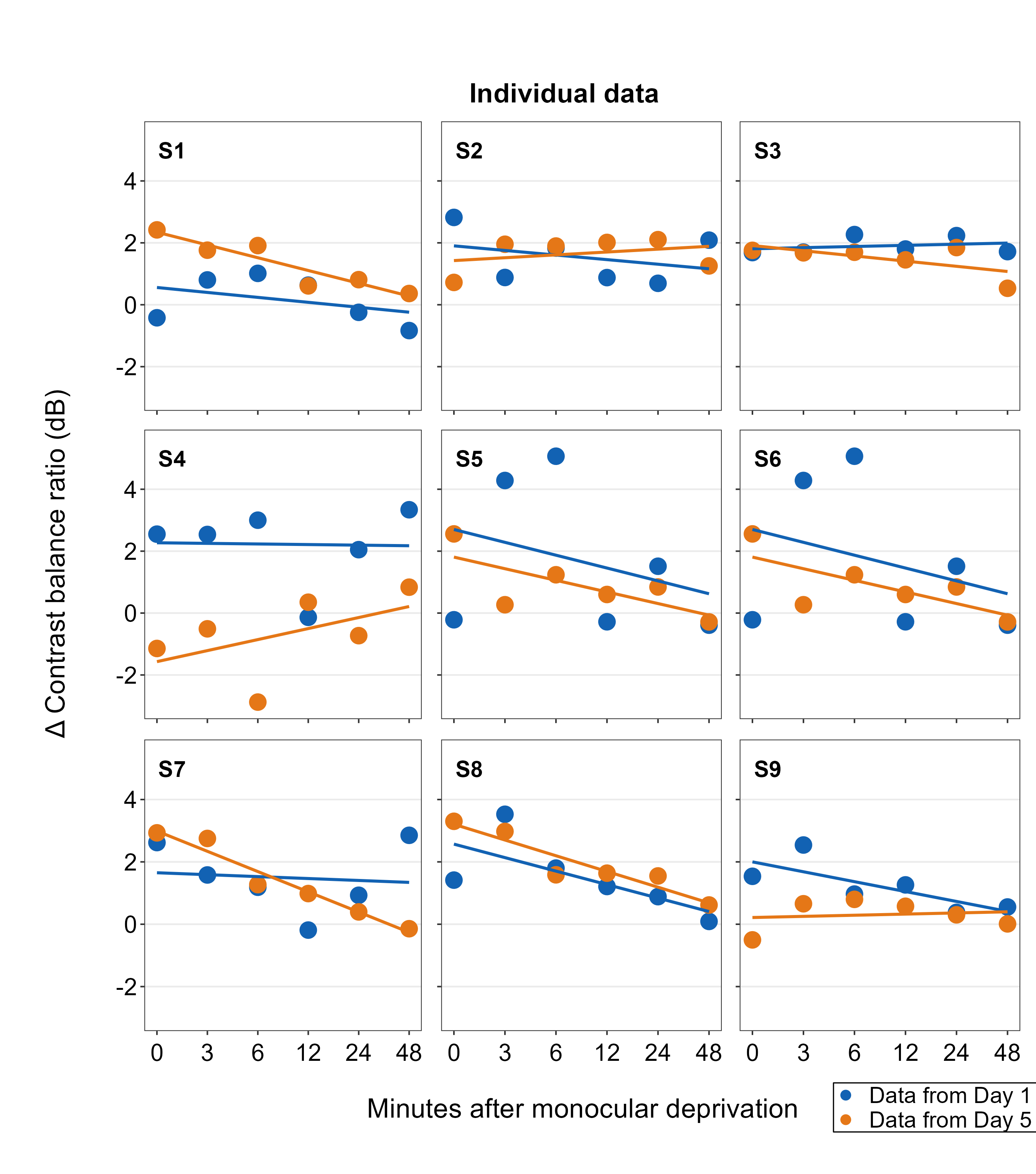
Also, besides sm_add_legend(), sm_put_together() can also legend onto the combined plot if the user supplies a separate legend input: ex. sm_put_together(legend = legend), where legend is a separate legend created as shown above. If the legend is provided in sm_put_together(), the function will automatically add legend onto the last panel of the combined plot, so make sure that the last empty panel is empty. The x and y coordinates howeevr are determined using sm_common_legend(), which we have opted for their defaults x=0.5 and y=0.5, ex. sm_common_legend(title=FALSE, legend_spacing=1, x=0.5, y=0.5) in the above.
To demonstrate this function, we will make a combined figure with 2 rows and 5 columns.
xlabel <- sm_common_xlabel("Minutes after monocular deprivation", x = 0.51, y = 0.6)
ylabel <- sm_common_ylabel("\u0394 Contrast balance ratio (dB)", x = 0.7)
title <- sm_common_title("Individual data", y = 0.3, x = 0.51, size = 18)
plots_tgd4 <- sm_put_together(all_plots,
title = title, xlabel = xlabel,
ylabel = ylabel, legend = legend,
ncol = 5, nrow = 2, hmargin = -5, wmargin = -5
)The arguments of sm_put_together() have to be written in this order unless they are specified (ex. sm_put_together(all_plots=all_plots, xlabel=xlabel, title=title)).
The title, xlabel, xlabel2, ylabel and ylabel2 can be provided as string characters, as shown below. If characters are provided rather than the outputs of sm_common_title(), sm_common_xlabel() and sm_common_ylabel(), then their locations cannot be modified. Their sizes can be adjusted using labelRatio argument. A value of 1 refers to the optimized text size, and 1.1 will be 0.1x larger than the optimized size. The text size optimization and the text locations are set by a simple algorithm that relies on the plot’s layout and other information to give optimal values. labelRatio only adjusts the text sizes when the label inputs are supplied as character strings, and they wont change text sizes when these have been created with sm_common_title(), sm_common_xlabel() and sm_common_ylabel().
7.5 Other important inputs of sm_put_together()
These inputs are automatically optimized (or adjusted) as default if the user does not supply input.
wRatio: controls the relative width of the panels in the left-most column of the composite plot with ticks for the primary y-axis.wRatio2: controls the relative width of the panels in the right-most column of the composite plot with ticks for the secondary y-axis. This gets activated if one of the plots in the input list has secondary y-axis.hRatio: controls the relative height of the panels in the bottom row of the composite plot with ticks for the primary x-axis.hRatio2: controls the relative height of the panels in the top row of the composite plot with ticks for the secondary x-axis. This gets activated if one of the plots in the input list has secondary x-axis.tickRatio: controls the relative text size of the tick labels on both axes of the outer panels in the composite plot.
However, it is possible that the optimization might not yield the best composite output, especially if users change the font sizes and because I cannot simply anticipate all possible plotting situations. So, users are encouraged to modify these arguments using values from 1.1 to 1.4.
labelRatio: controls the size of the titles (labels) of both axes. This gets activated only when users supply character inputs for the labels (title,xlabel,ylabel,xlabel2orylabel2). Otherwise, it gets ignored when users supply outputs fromsm_common_title(),sm_common_xaxis()andsm_common_yaxis().

7.6 Adding annotations to the composite figure
smplot2 enables users to add annotations on the final, combined figure with a full flexibility. Here are some examples using both functions of smplot2 and annotate() from ggplot2. Theoretically, users can also use functions from other packages. Except for sm_add_legend(), sm_add_point() and sm_add_text() functions are added modularly to the composite plot (output from sm_put_together()) as shown below.
7.6.1 Text annotations
Text annotations can be added to the composite figure using sm_add_text(). The label argument can be used to specify the text label. x and y are the coordinate values of the text in the composite figure, and they have to be between 0 and 1; 0.5 represents the origin (center) of the composite figure. size determines the text size and the fontface can be either bold, plain, italic or italic.bold.
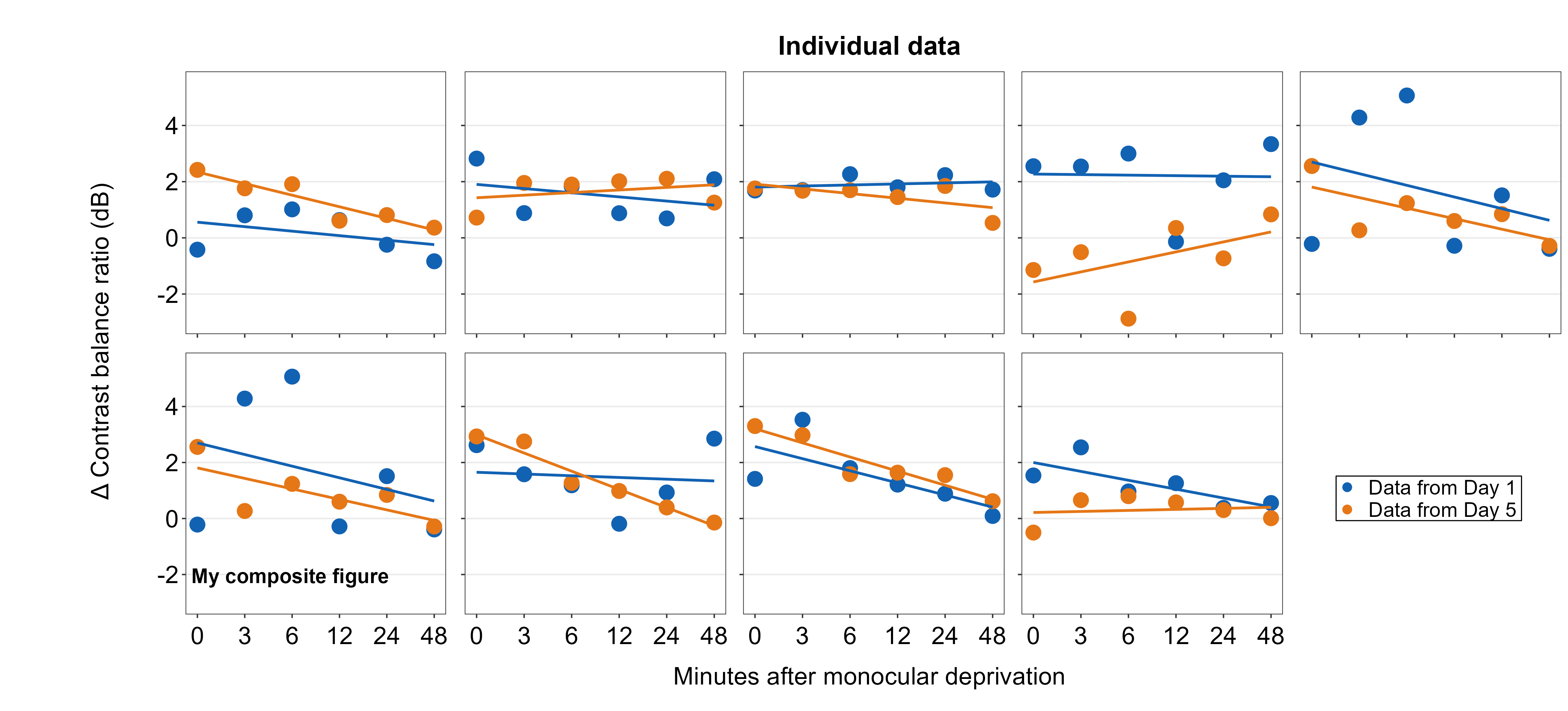
plots_tgd4b <- plots_tgd4 + sm_add_text(
label = "My composite figure",
x = 0.185, y = 0.19, size = 14, fontface = "bold"
)
7.6.2 Point annotations
Point annotations can be added to the composite figure using sm_add_point(). x and y are the coordinate values of the point in the composite figure, and they have to be between 0 and 1; 0.5 represents the origin (center) of the composite figure. size determines the point size and the shape number input should be the same as the ones in ggplot2 (ex. 21 is circle with border). fill should be provided for shapes with border. If the shape has no border, then color is sufficient to set the color that fills the point.
plots_tgd4c <- plots_tgd4b + sm_add_point(
x = 0.50, y = 0.50, size = 35,
shape = 21, fill = "gray80", color = "black"
)
7.6.3 Line annotations
Line annotations can be added to the composite figure using annotate(). x and y are the starting coordinate values of the line in the composite figure. xend and yend are the ending coordinate values of the line. These coordinate values have to be between 0 and 1; 0.5 represents the origin (center) of the composite figure. linewidth determines the width of the line and the color should adjust the color of the line. There is no fill argument.
plots_tgd4e <- plots_tgd4c +
annotate("segment",
x = 0.5, y = 0.475, xend = 0.5,
yend = 0.525, color = "black"
) +
annotate("segment",
x = 0.49, y = 0.5, xend = 0.51,
yend = 0.5, color = "black"
)
You can also use third-party annotation functions to annotate the composite figure generated from sm_put_together().
7.7 Why use sm_put_together()? (Advanced)
The primary reason for its existence is that the function has been designed to change the workflow of ggplot2 for subplotting and creating a composite figure by integrating the programmatic approach, which is not commonly used among users of ggplot2 because they otherwise risk losing flexibility for aesthetics and control.
A programming approach refers to a means that involves creating programming constructs, such as a for loop, if conditionals or vertorization, to minimize the length of code and improve the speed for computing to perform a complex task. Creating a composite plot with many panels, such as the example here, is a type of complex data visualization whose procedure can appear to be repetitive and cumbersome.
In this short example, I recreate the composite plot generated above using the function lapply(), which creates an iterative loop, producing one ggplot2 object per loop. There will be nine loops total, and these will be stored in the output object all_figs. More basic details about the function lapply() can be found in this tutorial.
subj_list <- paste0("S", 1:9)
all_figs <- lapply(1:length(subj_list), function(i) {
df_subj <- df %>% filter(Subject == subj_list[[i]])
ggplot(data = df_subj, aes(x = Time, y = Cbratio, color = Day)) +
geom_point(size = 4.5) +
geom_smooth(method = "lm", se = F, size = 0.9) +
# lm = linear regression method
scale_x_continuous(
breaks = unique(df$Time),
labels = c("0", "3", "6", "12", "24", "48")
) +
sm_hgrid() +
scale_color_manual(values = sm_color("blue", "orange")) +
scale_y_continuous(limits = c(-3, 5.5))
})We see that all_figs has nine plots and that it is a list structure, which can be handled by sm_put_together() to generate a composite plot.
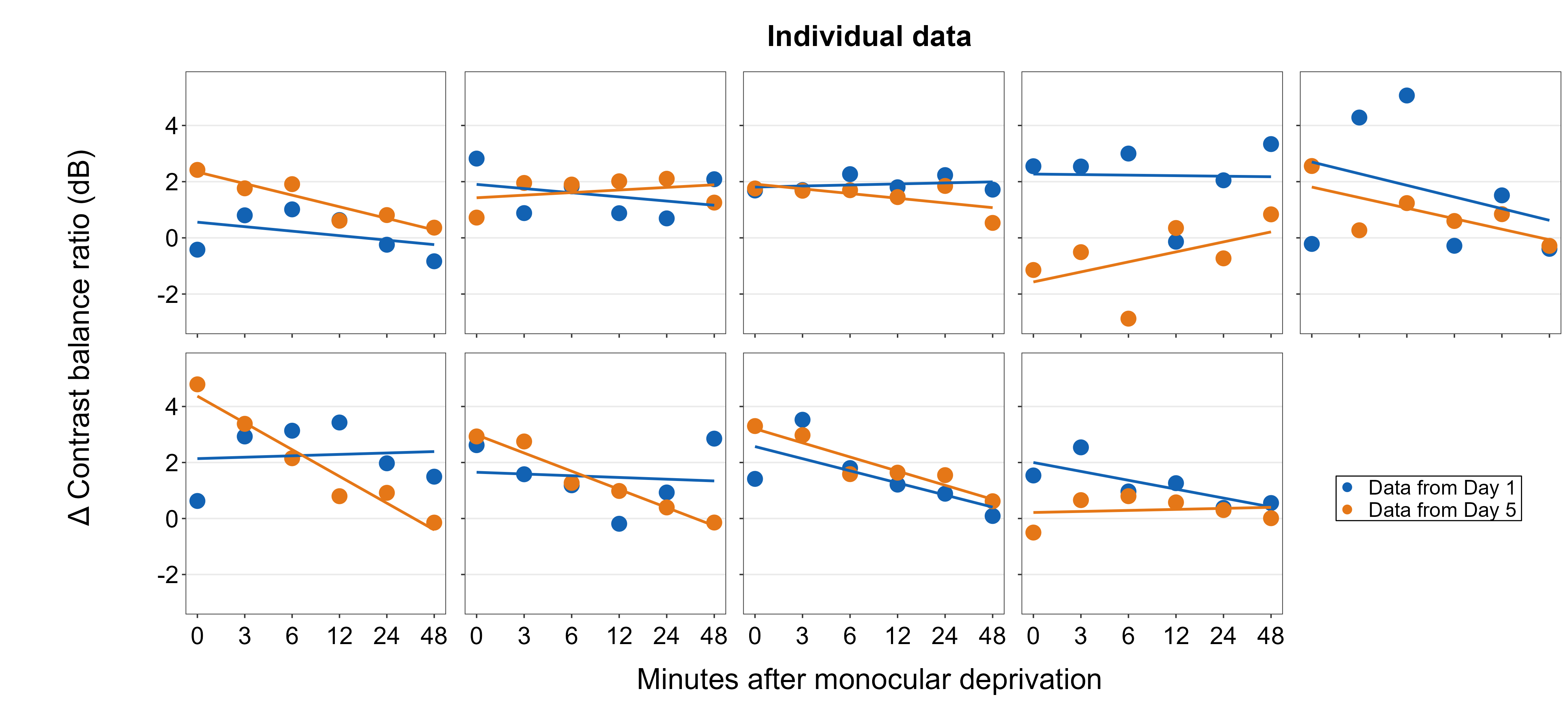
plots_tgd5 <- sm_put_together(all_figs,
title = "Individual data",
xlabel = "Minutes after monocular deprivation",
ylabel = "\u0394 Contrast balance ratio (dB)", legend = legend,
labelRatio = 0.95, ncol = 5, nrow = 2, hmargin = -5, wmargin = -5
)sm_put_together() can also handle nested list objects (i.e., list of list), so users can fully integrate complex programming constructs into their visualization routines to perform sophisticated data visualizations without relying on external packages.
To create a mosaic, where there is an empty panel in the every other panel, simply create an empty plot ggplot(NULL) + sm_common_legend() inside the lapply() construct.
ncol <- 5
nrow <- 4
numPanels <- ncol * nrow
subj_list <- paste0("S", 1:10)
i <- 0
figs_mosaic <- lapply(1:numPanels, function(iPlot) {
if (iPlot %% 2 == 0) {
ggplot(NULL) +
sm_common_legend() # empty panel
} else if (iPlot %% 2 == 1) {
i <<- i + 1
df_subj <- df %>% filter(Subject == subj_list[[i]])
ggplot(data = df_subj, aes(x = Time, y = Cbratio, color = Day)) +
geom_point(size = 4.5) +
geom_smooth(method = "lm", se = F, size = 0.9) +
# lm = linear regression method
scale_x_continuous(
breaks = unique(df$Time),
labels = c("0", "3", "6", "12", "24", "48")
) +
sm_hgrid() +
scale_color_manual(values = sm_color("blue", "orange")) +
scale_y_continuous(limits = c(-3, 5.5))
}
})sm_put_together() provides a limitless possibility of creating a composite plot with expressive layouts of subplots, as shown below.
mosaic_tgd <- sm_put_together(figs_mosaic,
title = "Mosaic of individual data",
xlabel = "Minutes after monocular deprivation",
ylabel = "\u0394 Contrast balance ratio (dB)",
labelRatio = 0.95, ncol = ncol, nrow = nrow, hmargin = -5, wmargin = -5
)
mosaic_tgd1 <- sm_add_legend(mosaic_tgd, x = 0.555, y = 0.2, legend = legend)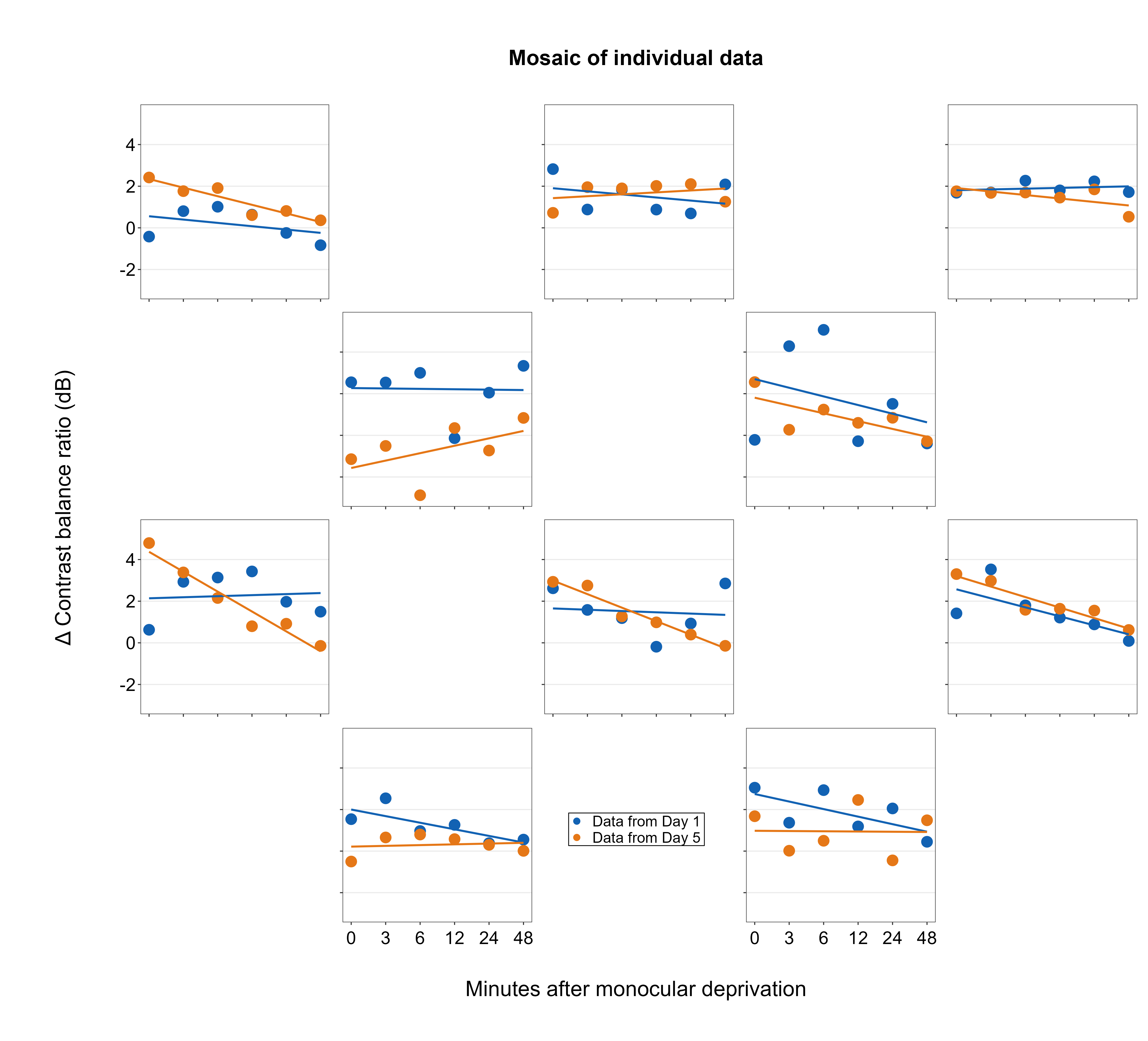
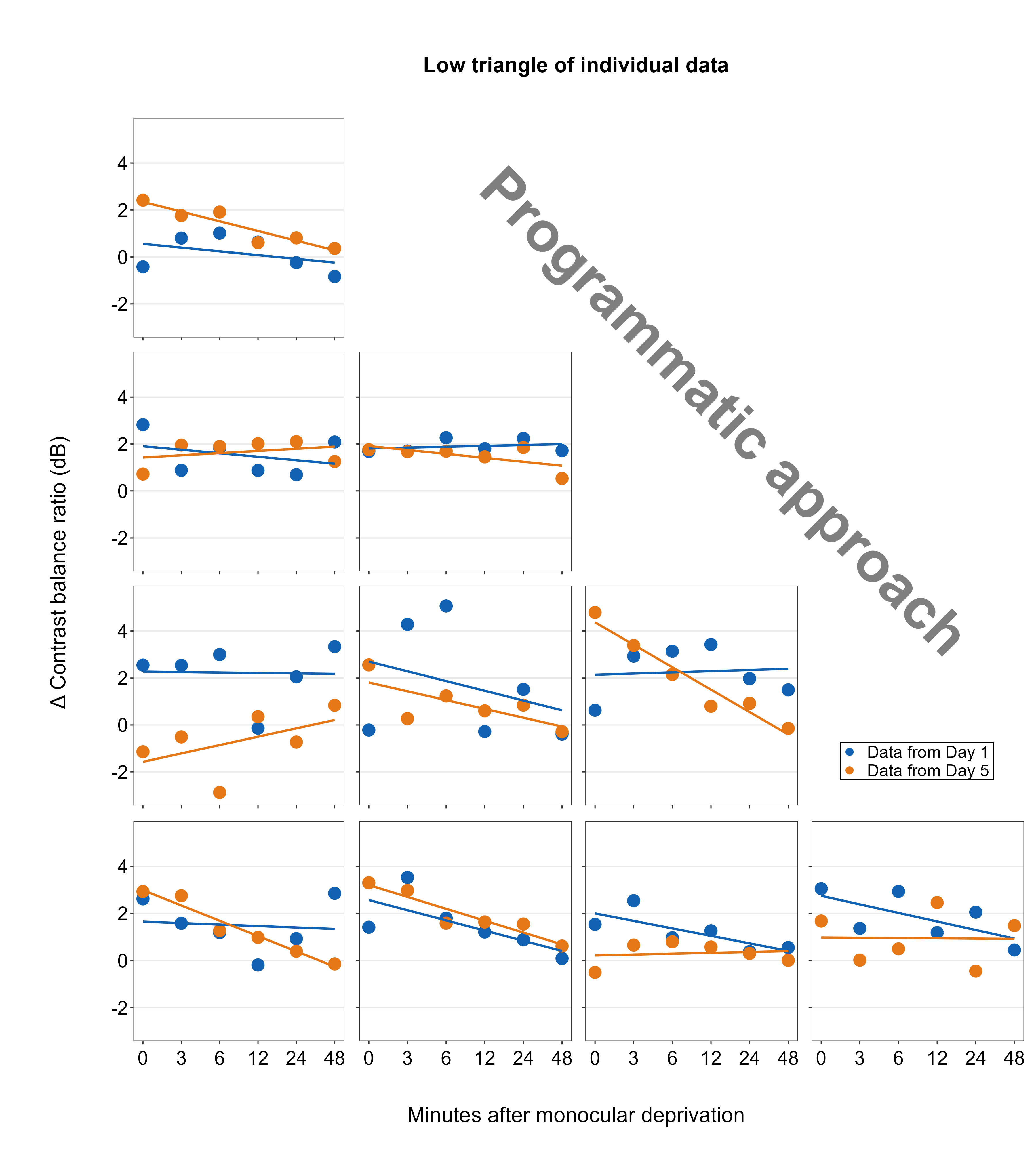
In this last example, we will organize the subplots using the configuration of a lower triangular matrix.
ncol <- 4
nrow <- 4
numPanels <- ncol * nrow
subj_list <- paste0("S", 1:10)
i <- 0
low_triangle <- lapply(1:numPanels, function(iPlot) {
if (iPlot %in% c(2, 3, 4, 7, 8, 12)) {
ggplot(NULL) +
sm_common_legend() # empty panel
} else {
i <<- i + 1
df_subj <- df %>% filter(Subject == subj_list[[i]])
ggplot(data = df_subj, aes(x = Time, y = Cbratio, color = Day)) +
geom_point(size = 4.5) +
geom_smooth(method = "lm", se = F, size = 0.9) +
# lm = linear regression method
scale_x_continuous(
breaks = unique(df$Time),
labels = c("0", "3", "6", "12", "24", "48")
) +
sm_hgrid() +
scale_color_manual(values = sm_color("blue", "orange")) +
scale_y_continuous(limits = c(-3, 5.5))
}
})
# Combine the subplots
low_tr_tgd <- sm_put_together(low_triangle,
title = "Low triangle of individual data",
xlabel = "Minutes after monocular deprivation",
ylabel = "\u0394 Contrast balance ratio (dB)",
labelRatio = 0.95, ncol = ncol, nrow = nrow, hmargin = -5, wmargin = -5
)
# Add legend
low_tr_tgd1 <- sm_add_legend(low_tr_tgd, x = 0.89, y = 0.35, legend = legend)
# Add annotation
low_tr_tgd2 <- low_tr_tgd1 + sm_add_text("Programmatic approach",
alpha = 0.5, x = 0.7, y = 0.65,
color = "black", size = 48, angle = 315,
fontface = "bold"
)
# Save figure
ggsave("low_tr.png", low_tr_tgd2,
width = 12,
height = 13.6
)